
El procesamiento del lenguaje natural (NLP) es un campo de la inteligencia artificial cuyo objetivo es brindar a las máquinas la capacidad de leer, comprender e interpretar el lenguaje humano. En los últimos años, debido a los avances en aprendizaje profundo y el desarrollo de los modelos secuenciales, el área del NLP ha tomado un papel relevante en diferentes industrias. Dentro de las aplicaciones más interesantes, objeto actual de investigación y desarrollo, se encuentran los procesos de validación de identidad a partir de lenguaje escrito y hablado. En este articulo presentamos estos conceptos e ilustramos aplicaciones para validación de identidad.
El “aprendizaje de máquina” son un conjunto de algoritmos con la capacidad de analizar datos y aprender reglas o patrones de ellos para luego hacer predicciones para una tarea específica (ej. tareas como saber si son la misma cara, la misma huella, o si un documento es auténtico o no). El aprendizaje de máquina ha derivado los adelantos en inteligencia artificial de la actualidad. En lugar de codificar a mano las rutinas de software con un conjunto específico de instrucciones y reglas para realizar una tarea en particular, la máquina se “entrena” automáticamente usando grandes cantidades de datos mediante algoritmos que le dan la capacidad de aprender cómo realizar la tarea [MANRIQUE2020-2].
El aprendizaje profundo se puede considerar como un subconjunto del aprendizaje automático derivado de los avances a nivel de algoritmos y hardware que permite entrenar modelos más complejos usando volúmenes de datos mucho más grandes. El aprendizaje profundo funciona con redes neuronales artificiales, que están diseñadas para imitar las interacciones neuronales del cerebro humano que gobiernan los procesos de aprendizaje y memorización. Hasta hace poco, el tamaño de las redes neuronales artificiales que se podían construir estaban limitadas por la potencia computacional y, por lo tanto, tenían aplicaciones limitadas. Sin embargo, diversos avances a nivel algorítmico, software y hardware han permitido construir modelos de redes neuronales más grandes y sofisticadas. Los asistentes virtuales como Alexa/Cortana, los carros que se conducen autónomamente, y los sistemas de traducción son algunos ejemplos de aplicaciones y sistemas de IA que funcionan con redes neuronales artificiales profundas.
Redes Neuronales Artificiales
Las redes neuronales artificiales están compuestas por capas de nodos, al igual que el cerebro humano está compuesto por neuronas.
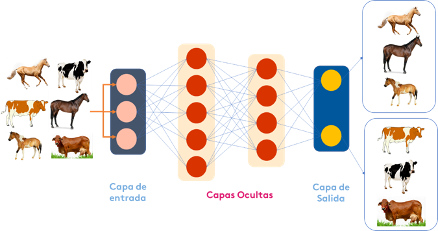
Figura 1. Red Neuronal Artificia
En la figura 1, se presenta la estructura de una red neuronal artificial convencional. La red está siendo entrenada para clasificar imágenes de vacas y caballos. Las imágenes son procesadas para ser representadas como un vector de pixeles de tamaño definido. Estos vectores ingresan a la red por la “capa de entrada” y se propagan a las denominadas “capas ocultas”. Como se observa en la figura los nodos dentro de capas individuales están conectados a capas adyacentes. Las líneas de conexión entre los diferentes nodos representan la propagación de la información la cual se realiza de forma ponderada a través de unos parámetros denominados “pesos”. Un nodo más “pesado” ejercerá más efecto en la siguiente capa de nodos. Cada nodo de la capa oculta procesa las entradas y coloca una salida en la siguiente capa oculta de acuerdo con una función de activación. La capa final compila las entradas ponderadas para producir una salida. La salida en este caso devuelve el resultado de la tarea de clasificación (¿es un caballo o es una vaca?).
¿Como se construye una red neuronal artificial? Para esto se deben aplicar algoritmos que obtienen los parámetros de la red (pesos). Estos algoritmos se alimentan con datos etiquetados para “aprender” los parámetros adecuados. En el ejemplo de la figura 1 los datos son miles de imágenes de vacas y caballos. Entre más data, más chances de obtener una red precisa en la tarea de clasificación.
Se dice que la red es más profunda en función de la cantidad de capas ocultas y nodos que tiene. La capacidad descriptiva de la red aumenta con el incremento de capas, sin embargo, es necesario grandes cantidades de datos para realizar un entrenamiento apropiado.
Procesamiento de Lenguaje Natural y Modelos Secuenciales
El procesamiento del lenguaje natural (NLP) es una forma de inteligencia artificial cuyo objetivo es brindar a las máquinas la capacidad de leer, comprender e interpretar el lenguaje humano. Para las computadoras, esto es algo extremadamente difícil de lograr debido a la gran cantidad de datos no estructurados y la ausencia de un contexto o intención del mundo real.
En los últimos años, debido a los avances en aprendizaje profundo, el procesamiento del lenguaje natural ha tomado un papel relevante en diferentes industrias. Los motores de búsqueda utilizan estrategias de NLP para generar resultados relevantes basados en un comportamiento de búsqueda similar o identificado la intención del usuario a partir de sus búsquedas previas. Los avances en NLP también han permitido el desarrollo de sistemas de traducción de lenguaje. Los traductores automáticos actuales tienen niveles de precisión altos comparables/superiores a traductores humanos. Las técnicas de análisis automático de sentimiento y polaridad, ampliamente usado en mercadeo y publicidad han sido también potenciadas por nuevas arquitecturas de redes neuronales profundas. Finalmente, los avances en generación de lenguaje hablado han permitido el desarrollo de asistentes virtuales como Alexa o Cortana.
Para construir aplicaciones avanzadas en NLP se han desarrollado nuevas arquitecturas y algoritmos que permiten procesar de mejor forma datos de naturaleza secuencial como el lenguaje escrito y hablado. Los denominados “modelos secuenciales” permiten lidiar con las características de orden/progresión propias del lenguaje que establecen las dependencias entre palabras. Dentro de los modelos secuenciales se popularizo por su efectividad las denominadas “Redes Neuronales Recurrentes” (RNN). Las redes neuronales recurrentes se crearon porque había algunos problemas con otras arquitecturas existentes de redes neuronales tanto clásicas como profundas:
- No pueden manejar datos secuenciales.
- Considera solo la entrada actual.
- No pueden memorizar entradas anteriores.
Las RNN son ideales para manejar datos de lenguaje (escrito o hablado) porque estos en esencia son secuencias de palabras relacionadas entre sí. La probabilidad de ocurrencia de una palabra depende de las anteriores e incluso de las futuras.
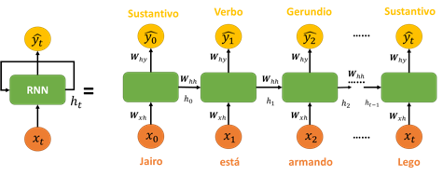
En la Figura 2 se muestra el diagrama típico de una RNN, especializada en etiquetar las palabras en una frase de tamaño t de acuerdo con su tipología (i.e. verbo, sustantivo, etc.). En cada momento t cada una de las palabras que componen la frase son incorporadas de forma secuencial a la RNN. En esta arquitectura discutida, la salida actual ŷt depende de las entradas y activaciones anteriores. En cualquier momento t, la entrada actual es una combinación de la entrada en xt y la salida de la capa inmediatamente anterior que recibió como entrada xt-1. En el ejemplo de la figura la palabra “armando” podría ser confusa (verbo, sustantivo) para otras arquitecturas de red, pero no para RNN ya que tienen en cuenta en este caso el resultado de las capas anteriores.
En algunos casos las dependencias entre palabras pueden ser más largas en el tiempo. Por ejemplo, en la frase “Los estudiantes, quienes estaban en medio de un examen, lograron concentrarse a pesar del ruido.”. La identificación de la forma conjugada correcta del verbo “lograr” depende no de las palabras inmediatamente anteriores “un examen”, pero sí de palabras mucho más atrás de la secuencia “Los estudiantes”. Estas dependencias de largo alcance en la secuencia se pueden modelar utilizando RNN con compuertas de memoria. Las denominadas Long Short-Term Memory (LSTM) y Gated Recurrent Units (GRU) son compuertas que se añaden a las RNN para regular el flujo de información manteniendo la información pasada que es relevante.
Aplicaciones de las RNN para validación de identidad
Una de las áreas donde las RNN han sido evaluadas es para la validación de identidad. La identidad expresada por la forma como la persona manipula el lenguaje escrito o hablado. La estilometría es un área de investigación que tiene por objeto identificar características principalmente lingüísticas a partir de palabras, estructuras sintácticas y semánticas que se encuentran en un texto escrito. Estas características suelen ser propias de la persona y pueden definir su estilo lingüístico [DAEL2013].
Las primeras investigaciones estilométricas fueron realizadas sobre texto escrito extenso producido por literatos (i.e. novelas, poemas, etc) [JUOLA2006]. Los resultados de los modelos computacionales construidos sugerían que el estilo era único y poco variable en el tiempo. Por ejemplo [SALEH2014] reportó precisiones superiores al 97% usando libros escritos por 10 diferentes autores. En entornos digitales y en particular en redes sociales, la atribución de autoría es mucho más desafiante debido al número gigantesco de usuarios, así como muestras de texto mucho más cortas.
Las redes RNN han probado ser métodos robustos para esta tarea [BEVENDORFF2020] y en general proveen de una mayor capacidad descriptiva que otros tipos de modelamiento. En la Figura 3 se observa de forma general una arquitectura de RNN que permite identificar el autor de un texto particular. En este caso la arquitectura se conoce como “Many to One” ya que la entrada son muchas palabras mientras que la salida es una sola y representa el posible autor.
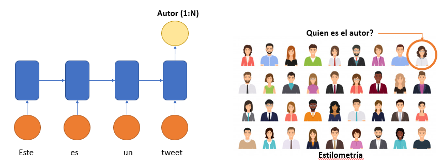
Fig 3. Arquitectura RNN “Many to One” para la identificación de autor
A pesar de los grandes avances con las LSTM, conclusiones de investigaciones recientes han mostrado la dificultad de utilizar el estilo lingüístico como método de validación de identidad [KALA2018, BEVENDORFF2020]. Entre los principales factores se encuentran:
1. El estilo de un autor cambia dependiendo del tópico sobre el cual habla/escribe (por ejemplo, política vs futbol).
2. El estilo de un autor dependen del escenario. El lenguaje empleado en redes sociales es diferente al usado en foros de y plataformas de Q&A.
3. Para obtener modelos de identificación precisos se requieren muestras de texto de longitud considerable. Estas son generalmente engorrosas de adquirir.
A pesar de que la estilometría no es viable en la actualidad como factor de identificación han surgido otros métodos de validación de identidad derivados de la producción de texto en ambientes digitales. El reconocimiento de la dinámica de pulsaciones (más conocido por su nombre en inglés keystroke dynamics) es otra forma de validación de identidad en la cual también se han empleado las RNN [LU2020, THE2013, LICHAO2017]. El reconocimiento de pulsaciones de teclas ha sido definido como el proceso de medir y evaluar un ritmo de escritura en dispositivos digitales como teclados de computadora, teléfonos móviles y en general dispositivos de pantalla táctil.
De acuerdo con los resultados reportados en [LICHAO2017] y [LU 2020] se tienen precisiones entre 84% y 95%, y dependen principalmente del número de usuarios contra los cuales debe comparar y la longitud de las secuencias de entrada con las cuales se construye el modelo de usuario.
Conclusión
Los avances en NLP impulsados por el aprendizaje profundo y representados en los denominados modelos secuenciales han permitido el desarrollo de muchas aplicaciones basadas en lenguaje. Los asistentes virtuales y traductores son ejemplos de dichos de avances. Su aplicación para procesos de validación de identidad, si bien están en desarrollo e investigación, es prometedora y existen adelantos que explotan la estilometría y la dinámica de tecleo.
Rubén Manrique
Bibliografía
[THE2013] Teh PS, Teoh AB, Yue S. (2013) A survey of keystroke dynamics biometrics. ScientificWorldJournal. 2013;2013:408280. Published 2013 Nov 3. doi:10.1155/2013/408280
[DAEL2013] Daelemans W. (2013) Explanation in Computational Stylometry. In: Gelbukh A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2013. Lecture Notes in Computer Science, vol 7817. Springer, Berlin, Heidelberg.
[BEVENDORFF2020] Janek Bevendorff. (2020) Overview of PAN 2020: Authorship Verification, Celebrity Profiling, Profiling Fake News Spreaders on Twitter, and Style Change Detection.[JUOLA2006] P. Juola, J. Sofko, P. Brennan A Prototype for authorship attribution studies Literary Linguist. Comput., 21 (2) (2006), pp. 169-178
[MANRIQUE2020] Rubén Manrique. (2020) Identidad digital basada en texto: estrategias, avances y limitaciones.
[MANRIQUE2020-2] Rubén Manrique. (2020) Inteligencia artificial y su impacto en verificación de identidad.
[KALA2018] Sundararajan, Kalaivani (2018). Analysis of Stylometry as a Cognitive Biometric Trait.
[PAWEL2016] Kobojek, Paweł and K. Saeed (2016). Application of Recurrent Neural Networks for User Verification based on Keystroke Dynamics.
[LICHAO2017] Sun, Lichao et al. (2017). Sequential Keystroke Behavioral Biometrics for Mobile User Identification via Multi-view Deep Learning.
[LU2020] Xiaofeng Lu, Shengfei Zhang, Pan Hui, Pietro Lio (2020) Continuous authentication by free-text keystroke based on CNN and RNN, Computers & Security.


